Published Jun 28, 2026
Making a Website Indexable, Usable, and Recommendable for AI Systems
AI visibility starts with the same foundations that make a website easy to crawl, parse, trust, and cite. This article explains how to align technical SEO, structured data, content architecture, crawler controls, rights management, and measurement for AI-assisted search and recommendations.
Category: SEO & Web Marketing · Author: Mikalai Sasau
This article explains how to make a website easier for AI systems to crawl, understand, trust, cite, and recommend. It translates platform guidance from Google, OpenAI, Microsoft/Bing, Anthropic, Meta, and related technical sources into a practical SEO and content architecture workflow.
Practical default: do not treat AI visibility as a separate magic layer. First make the site indexable, canonical, text-first, structured, current, and easy to verify. Then add assistant-facing improvements such as stronger internal links, clear source attribution, feeds, transcripts, and, where useful, app or API access.
Use this as a practical checklist if your site needs to appear in AI answers: allow the right crawlers, publish canonical URLs in sitemaps, keep important content in HTML text, show authorship and update dates, use structured data that matches the visible page, and make key claims easy to verify from primary sources.
Executive summary
The short version is surprisingly simple: the strongest way to
improve a site’s visibility in AI assistants is still to make it easy to
crawl, easy to parse, easy to trust, and easy to cite. Across OpenAI,
Google, Microsoft/Bing, and Anthropic, the official guidance converges
on a familiar foundation: do not block the relevant crawlers, expose
clean canonical URLs, publish complete sitemaps, use structured data
that matches visible content, maintain strong internal linking, and keep
pages factually accurate, current, and attributable. Google is
especially explicit that there is no special AI-only markup
requirement for AI Overviews or AI Mode; a page simply needs to
be indexable and snippet-eligible in Search. OpenAI is similarly
explicit that sites must allow OAI-SearchBot to be
surfaced in ChatGPT search, while Anthropic documents separate bots for
model training, user-initiated fetches, and search indexing.
Microsoft/Bing now frames the same SEO foundation as the basis not only
for search ranking but also for Copilot grounding and citation
eligibility.
The practical implication is that “AI optimization” is not really a
separate discipline from technical SEO and information architecture. It
is technical SEO plus retrieval design plus rights management. For most
websites, the highest-return work is to fix crawlability,
canonicalization, metadata, structured data, freshness, and page-level
clarity before experimenting with anything exotic. A second layer then
improves retrieval quality for LLMs: text-first page structure,
semantically coherent sections, explicit authorship, dates, citations,
FAQs, tables, transcripts, and stable entities. A third layer broadens
recommendation surfaces through strong internal links, authoritative
external mentions, feeds, media packaging, and, where relevant, a
read-only API or an MCP- or app-based interface for assistants.
One caution matters more in 2026 than it did a year ago: publishers
now have more granular controls, but they differ by platform. OpenAI
separates ChatGPT search from model training through
OAI-SearchBot versus GPTBot. Anthropic
separates Claude-SearchBot, ClaudeBot,
and Claude-User. Google separates Search generative AI
inclusion controls in Search Console from
Google-Extended, which governs training and some
grounding uses outside Search. If you accidentally block the wrong bot,
you can lose AI visibility without meaning to.
The most important strategic recommendation is this: build pages so they can stand alone as cited evidence. AI systems increasingly retrieve section-level evidence, not just page-level “SEO pages.” If a page has a clear claim, a clear source, a visible date, a named author or organization, stable canonical URLs, machine-readable entities, and extractable text around each answer-sized topic, it is far more likely to be surfaced, grounded, summarized, and recommended. That is the practical center of gravity for AI discoverability.
What the major platforms actually recommend
The biggest misconception in this market is that every platform needs
its own secret optimization playbook. The official sources say
otherwise. Google states that the usual SEO best practices remain
relevant for AI Overviews and AI Mode, and that there are no extra
technical requirements beyond being indexed and eligible to appear with
a snippet. It also says site owners do not need “new
machine readable files, AI text files, or markup” to appear in those
experiences. OpenAI says any public site can appear in ChatGPT search,
but sites that want to be summarized and cited must not block
OAI-SearchBot. Microsoft/Bing says the same core SEO
practices that improve discovery, indexing accuracy, URL consolidation,
content clarity, and authority also support Copilot grounding and
citation eligibility. Anthropic likewise documents a dedicated search
bot and says blocking it may reduce visibility in user search results.
That convergence is useful because it means you can prioritize a
single durable operating model instead of chasing vendor-specific hacks.
The durable model is: publish clean public URLs, let the relevant robots
access them, describe them clearly, and keep them worth citing. What
differs by platform is mainly the control surface. OpenAI’s controls are
in robots.txt via OAI-SearchBot and
GPTBot. Anthropic’s are
Claude-SearchBot, Claude-User, and
ClaudeBot, plus support for Crawl-delay.
Google uses normal Search controls for Search inclusion, plus a Search
Console generative AI control for AI features in Search, and
Google-Extended for training and some grounding uses
outside Search. Microsoft/Bing adds IndexNow, a URL Submission API,
crawl control, and an AI Performance report that shows which pages are
actually cited in Copilot and related AI experiences.
For Meta, the most relevant public, webmaster-facing guidance in the
sources reviewed is not an AI crawler program but structured
presentation for distribution and recommendations through Open
Graph metadata and Meta’s Sharing Debugger.
That matters because recommendation engines are broader than answer
engines, and social surfaces still influence what gets discovered,
linked, and “known.” If a page is likely to be shared, the Open Graph
canonical URL, title, image, locale, and description should be treated
as first-class metadata.
| Platform | What official docs say | What to do in practice | Expected impact | Effort |
|---|---|---|---|---|
| OpenAI | OAI-SearchBot controls appearance in ChatGPT search; GPTBot controls
training use; ChatGPT-User is for user-initiated visits. |
Allow OAI-SearchBot for pages you want cited; decide
separately on GPTBot; avoid relying on user-triggered
fetches for discoverability. |
High for ChatGPT search visibility | Low |
| No special AI markup is required; AI Overviews/AI Mode use normal Search eligibility and snippet controls. | Focus on indexability, snippets, internal links, text availability, structured data, and page quality. | Very high | Medium | |
| Microsoft/Bing | SEO fundamentals also support grounding and citations across Bing and Copilot. | Use sitemaps, IndexNow, clean URLs, structured data, and
authority-building links; monitor AI Performance. |
High | Medium |
| Anthropic | Separate bots for training, search indexing, and user-initiated
retrieval; Crawl-delay supported. |
Allow Claude-SearchBot and, if desired,
Claude-User; throttle with Crawl-delay if
needed. |
Medium to high | Low |
| Meta | Open Graph turns web pages into rich graph objects; Sharing Debugger
previews how pages render when shared. |
Treat OG tags as recommendation metadata for social discovery and downstream linking. | Medium | Low |
A final platform-level recommendation is more strategic than
technical. If your business depends on being usable by
assistants, not just indexed by them, publishing public web pages may
not be enough. OpenAI now provides an Apps SDK and
MCP-based app surface for ChatGPT, while MCP itself is an open standard
for connecting AI applications to external systems. For complex content,
logged-in data, live inventory, calculators, or comparison tools, an
assistant-facing interface can outperform passive web crawling because
it gives the model clean, structured, permission-aware access to your
content and functions.
Build a crawlable, machine-readable technical foundation
At the technical layer, the job is not to “please the model.” It is
to reduce ambiguity. The minimum viable stack is still the classic trio:
robots, sitemaps, and canonicalization. The robots protocol is now an
Internet standard under RFC 9309, but the standard itself is explicit
that it is a crawl control mechanism, not access authorization. Google
also warns that robots.txt cannot reliably hide content from search
results, because blocked URLs can still be indexed if they are linked
from elsewhere. So use robots.txt to manage crawl traffic and
bot-specific behavior, but use noindex, removal workflows,
or authentication when you need actual non-appearance.
A practical robots policy should distinguish between search
inclusion, training use, and user-triggered retrieval. This is now
operationally important.
User-agent: OAI-SearchBot
Allow: /
User-agent: GPTBot
Disallow: /
User-agent: Claude-SearchBot
Allow: /
User-agent: Claude-User
Allow: /
User-agent: ClaudeBot
Disallow: /
User-agent: Googlebot
Allow: /
User-agent: Google-Extended
Disallow: /
Sitemap: https://example.com/sitemap.xmlThis pattern reflects the official separation between OpenAI search
and training bots, Anthropic’s search versus training versus user bots,
and Google’s Search crawling versus Google-Extended training/grounding
controls outside Search. OpenAI notes that robots.txt changes for search
generally take about 24 hours to adjust in its systems, while Google
says Search generative AI control changes generally take a few days and
that some cached content can take longer to clear.
Sitemaps remain the clearest large-scale URL discovery and canonical
hint mechanism. Google supports XML, text, RSS, mRSS, and Atom formats,
recommends UTF-8 encoding, caps a single sitemap at 50 MB or 50,000
URLs, and explicitly says you should include the URLs you prefer to show
in results — in other words, your canonical URLs. It also supports
WebSub for Atom and RSS as a change broadcast mechanism. Bing supports
sitemap submission and strongly encourages IndexNow or URL submission
for faster updates.
Canonicalization is the next major control point, and it is often the
place where AI visibility quietly breaks. Google recommends
rel="canonical" as a strong signal, says it should use
absolute URLs, and notes that the HTTP header variant is the right
solution for non-HTML files such as PDFs. It also warns against using
inconsistent canonical signals across methods and against using
noindex as a substitute for canonicalization within one
site. Internally, link to canonical URLs consistently rather than
duplicate variants. For multilingual sites, hreflang must
use fully qualified alternate URLs, every version must reference itself
and its peers, and Google will ignore tags when the links are not
bidirectional.
Structured data is the machine-readable layer that helps reduce
ambiguity about entities, authorship, dates, media, and relationships.
Google says structured data helps it understand pages and explicitly
recommends JSON-LD when site architecture allows. For articles, it
recommends adding as many applicable properties as possible, including
author, headline, image, datePublished, and
dateModified, and says this can improve title text, image
handling, and date information across Search and other properties such
as Google News and Google Assistant. Schema.org’s license
property also gives you a clean place to signal usage rights for a
CreativeWork.
<script type="application/ld+json">
{
"@context": "https://schema.org",
"@type": "Article",
"headline": "How to choose project management software for remote teams",
"author": {
"@type": "Person",
"name": "Ava Singh",
"url": "https://example.com/authors/ava-singh"
},
"datePublished": "2026-06-10T09:00:00+02:00",
"dateModified": "2026-06-24T08:30:00+02:00",
"image": "https://example.com/images/pm-guide-cover.jpg",
"license": "https://example.com/licensing",
"mainEntityOfPage": "https://example.com/guides/remote-pm-software"
}
</script>If you want faster propagation, use APIs where the platform offers
them. Google’s Search Console API lets verified owners submit sitemaps
programmatically. Bing’s URL Submission API supports up to 10,000 URLs
per domain per day, while IndexNow supports up to 10,000 URLs per POST
and is designed to be automated whenever content is added, updated, or
deleted. That makes IndexNow particularly attractive for newsrooms,
marketplaces, documentation centers, and any site whose “freshness
footprint” matters for assistant answers.
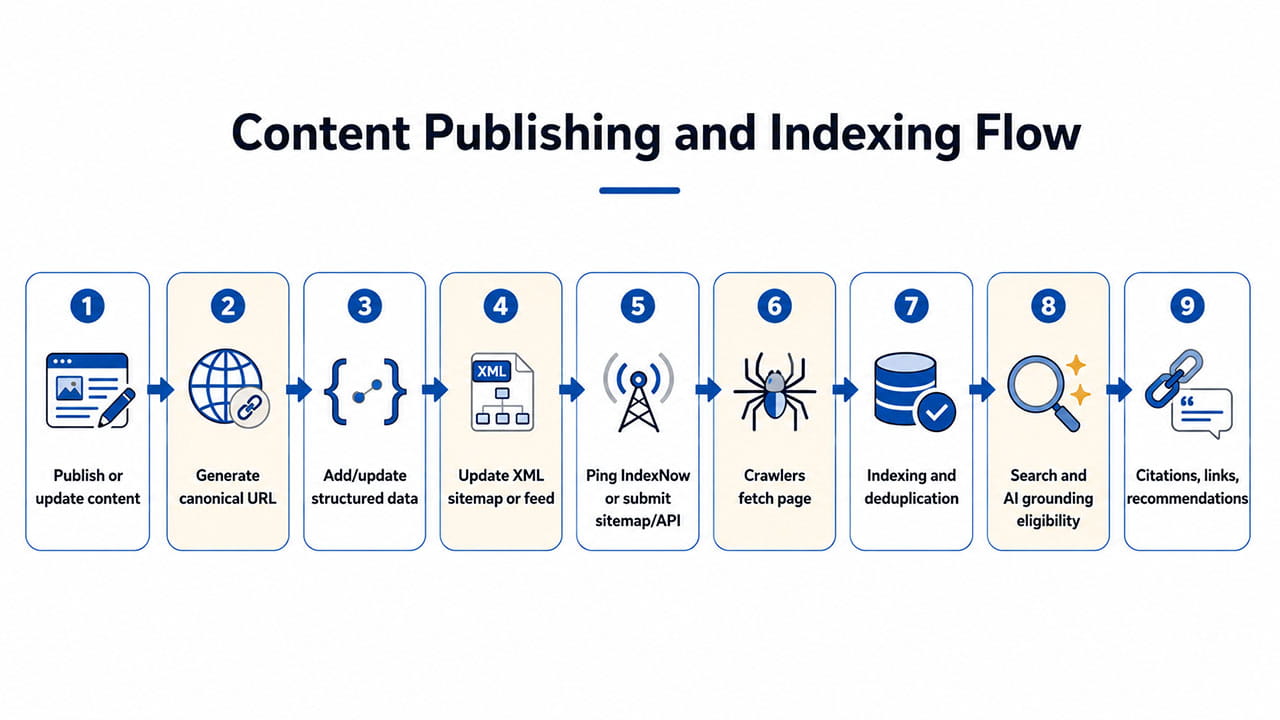
Publish content that retrieval systems can trust and reuse
This is where traditional SEO often stops too early. AI systems do not just rank pages; they retrieve passages, infer entities, compare claims, and decide what to cite. That means content architecture now matters almost as much as content topic.
The safest content rule is to optimize for extractable evidence, not
just keywords. Google’s people-first content guidance explicitly points
site owners toward E-E-A-T-informed self-assessment, while Google’s
byline guidance recommends visible publication and update dates plus
structured datePublished and dateModified. Its
AI features guidance also says important content should be available in
textual form. Put differently: if the page’s key answer only exists in a
graphic, an interactive widget, or a buried PDF attachment, you are
making retrieval harder than it needs to be.
Research on RAG systems reinforces the same point from the model
side. Recent ACL work shows document segmentation materially affects
retrieval accuracy because overly large chunks introduce irrelevant
information while overly small chunks lose semantic coherence.
Microsoft’s Azure AI Search documentation similarly says partitioning
large documents into chunks helps meet token limits, prevents
truncation, and often improves representation when a single page spans
many subtopics. Google Cloud’s Agent Search documentation recommends
chunking and layout parsing because indexing by coherent chunks improves
relevance and reduces compute load for LLMs.
For publishers and site owners, that research translates into concrete editorial rules. Do not write giant undifferentiated walls of text. Use descriptive H2 and H3 headings. Keep each section about one clear subtopic. Prefer explicit question-and-answer blocks for FAQs and support content. Put tables near the claims they support. State definitions once, clearly. Add summary boxes where appropriate. If a single page covers ten separate intents, consider splitting it into a hub page plus focused child pages. Those are not just readability improvements; they create cleaner retrieval units.
Factuality and citations deserve special emphasis. A 2025 Nature
Communications study found large rates of unsupported or contradicted
statements even when LLMs cite sources, which is a strong reason to make
original sourcing on your own pages unmistakable. If you quote a law,
standard, study, pricing schedule, or benchmark, link to the primary
source. If you make a claim that can change, timestamp it. If you update
a page, say what changed. If a piece is opinion, label it as opinion.
The easier you make claim verification, the easier you make safe reuse
by assistants that care about grounding quality.
OpenAI’s retrieval and file-search documentation also points toward an important design pattern: semantic search works by comparing relatedness, not just keyword matching, and vector stores can use both semantic and keyword retrieval over uploaded files. That means you should think in terms of entity-rich, semantically distinctive language rather than generic copy. Pages that repeatedly use vague phrases like “our solution,” “best-in-class,” or “innovative platform” give embeddings very little to anchor to. Pages that clearly name the product, use case, target audience, constraints, examples, and comparative terms are much easier to retrieve and rerank.
| Content signal | Why it matters for LLMs and retrieval | Required action | Expected impact | Effort |
|---|---|---|---|---|
| Visible authorship and organization | Helps users and systems assess provenance and E-E-A-T. | Add author pages, organization identity, and matching structured data. | High | Medium |
| Publication and update dates | Supports freshness estimation and date display in search. | Show visible “Published” / “Updated” dates and schema dates. | High | Low |
| Section-level coherence | Improves chunk quality and retrieval precision. | Rewrite long pages into semantically coherent sections with headings. | High | Medium |
| Cited claims and primary sources | Reduces ambiguity and increases trust for grounded answers. | Link to official sources for statistics, legal claims, specs, and research. | High | Medium |
| Text availability | Search and AI systems need important material in extractable text. | Add transcripts, alt text, summaries, and HTML equivalents for key
assets. |
High | Medium |
| Distinctive terminology and entities | Improves semantic retrieval and recommendation matching. | Use precise nouns, named entities, tasks, audiences, and constraints. | Medium to high | Low |
Strengthen authority with links, citations, and media packaging
Once the technical base is stable and the content is structured for retrieval, the next layer is what marketers would still call authority — but authority now has two audiences: ranking systems and answer engines. Google’s Search Essentials still says to make links crawlable, use the words people search for in prominent locations, and tell people about your site in relevant communities. Bing’s guidelines now explicitly connect authority and trust signals to grounding eligibility and long-term visibility across Bing, Copilot, and AI-powered search experiences. Bing’s link-building guidance is equally direct: quality matters more than volume, and a few trusted inbound links can outperform a flood of low-quality ones.
Internal links do more work in AI retrieval than many teams realize. Google explicitly lists internal links as a way to make content easily findable for AI features, and it recommends linking internally to canonical URLs. In practice, this means your hub pages, comparison pages, glossaries, author pages, and category pages should not be decorative. They should be strong discovery nodes that connect related intent clusters. A good internal link graph helps crawlers discover pages, helps search engines understand topical neighborhoods, and helps retrieval systems find corroborating context around an answer.
External citations matter for a broader reason than “link juice.”
When trusted third parties mention your brand, product, research, or
dataset, they create independent evidence that retrieval and ranking
systems can triangulate. The official docs do not present this in
academic RAG vocabulary, but Bing’s emphasis on authority and trust
signals and Google’s emphasis on people-first, reliable content point in
the same direction. My inference is that the best external mentions are
the ones that are both topically relevant and semantically aligned with
the claims you want to be surfaced for. A citation from an industry
standard body, a university lab, a trade publication, or a respected
open-source ecosystem is usually more valuable for AI surfacing than a
generic directory listing.
Media format choices also matter. Google can index most text-based
files and a long list of image and video formats, but HTML still gives
you the richest control over headings, links, metadata, and structured
data. Use HTML as the primary landing format for important evergreen
content. Where PDFs are necessary, publish an HTML summary or full HTML
twin and use canonical signals thoughtfully. For videos, Google
recommends a dedicated watch page, stable media URLs, video structured
data, and accessibility for the actual video bytes if you want full
video features. For images, it emphasizes image discovery, supported
formats, captions, and image SEO practices. For social and
recommendation surfaces, Open Graph gives you a canonical object URL,
title, image, description, locale, and site name.
Feeds are the overlooked format in this stack. Google supports RSS,
mRSS, and Atom as sitemap formats and explicitly notes that Atom or RSS
publishers can use WebSub to broadcast changes. If your site publishes
news, releases, product updates, documentation changes, or research
briefs, a clean feed can improve downstream ingestion by both search
systems and third-party monitoring tools that often seed recommendation
flows.
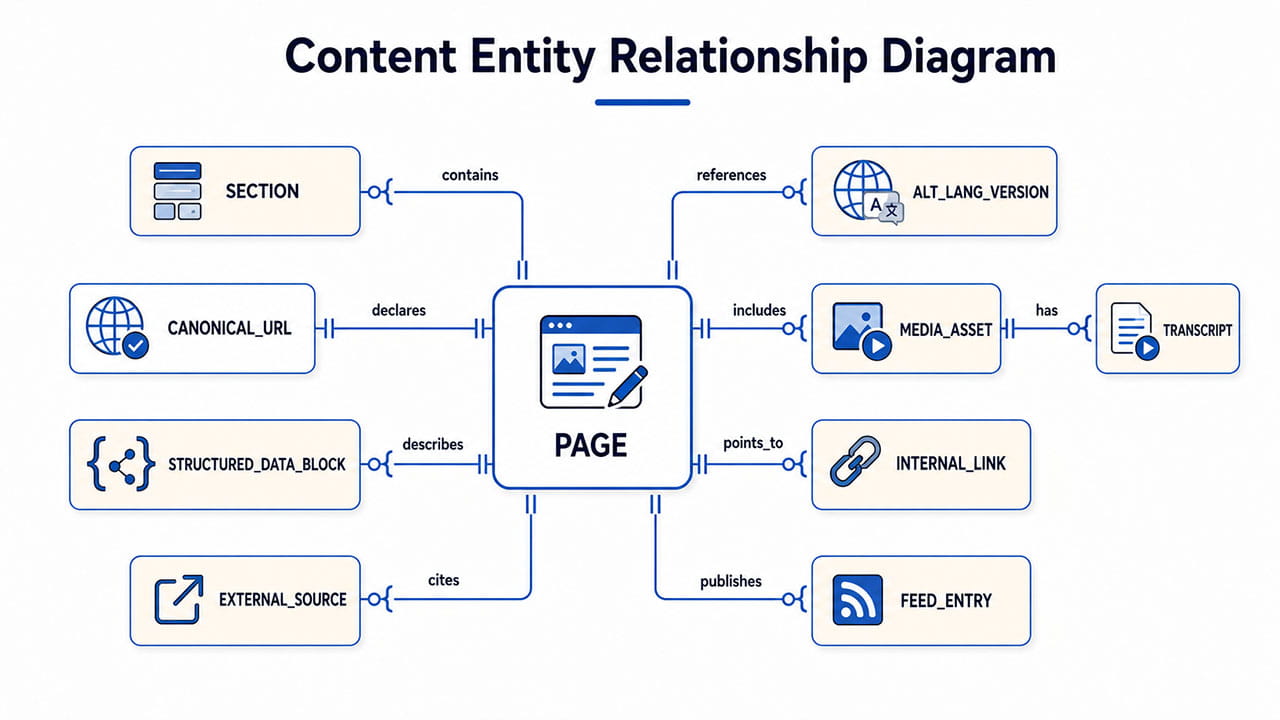
Handle rights, privacy, and participation controls carefully
The mistake many teams make is to treat robots.txt as if it were a
complete AI rights strategy. It is not. RFC 9309 defines robots as a way
to control crawler access behavior, not a legal authorization framework.
Google echoes the same limitation in practical terms by warning that
robots rules do not reliably prevent URL indexing and that some crawlers
may not support all robots behavior. So if you care about licensing,
privacy, or contractual reuse conditions, you need layered controls:
robots where supported, correct indexing controls, clear license pages,
Terms of Use, restricted access for private material, and a privacy
program that matches what you publish.
On copyright and text/data mining, the EU position is especially
relevant. Article 4 of Directive (EU) 2019/790 requires Member States to
provide a text-and-data-mining exception for lawfully accessible works,
but it also says the exception applies only if the use has
not been “expressly reserved” by rightholders in an
appropriate manner, including machine-readable means for publicly
available online content. That does not automatically tell you which
vendors will honor which signal in every case, but it is an important
legal reason to express your preferences clearly and machine-readably
where you do want to reserve rights.
Licensing should be explicit, especially if you do want
reuse. Creative Commons provides standard legal tools for granting
public permissions, and Schema.org provides a license
property you can attach to creative works. If your strategy is to
maximize citation and reuse of knowledge content, developer docs, or
educational material, a clear rights statement lowers uncertainty for
both people and systems. But Creative Commons also warns that its
licenses are irrevocable and should only be applied by the rights holder
or someone who controls the copyright.
Privacy is the other non-negotiable layer. GDPR requires fair and
transparent processing disclosures, emphasizes data minimization, and
gives data subjects rights including rectification, erasure, and
objection in relevant cases. For public websites, the practical meaning
is straightforward: do not expose personal data in crawlable pages
unless there is a clear lawful basis and user expectation; avoid
publishing unnecessary email addresses, direct phone numbers, or case
details in indexable formats; and ensure your privacy notice explains
analytics, profiling, third-party recipients, and transfers where
relevant. If a page is not meant for open discovery, do not rely on
hidden UI elements or robots directives alone — keep it out of public
crawl space entirely.
A good governance model is to classify content into four buckets:
public and reusable; public but not for training; public but not for
snippet/AI display; and private/non-public. Then align your robots,
noindex, access controls, licenses, and privacy notice accordingly. The
biggest visibility losses I see now come from accidental policy
contradictions: for example, allowing crawl but blocking the snippet
needed for citation, or disallowing the search bot while wondering why
the site no longer appears in assistant answers.
Measure, test, and operationalize
You cannot improve AI discoverability if you only measure blue-link
SEO. The instrumentation stack has changed. On Google, the core official
tools remain Search Console’s URL Inspection, Index Coverage, Rich
Results reporting, and now the Generative AI performance
report, which shows impressions in AI Overviews and AI Mode,
including page, country, and device dimensions. Google also introduced a
Search Console control for opting into or out of Search generative AI
features. On Bing, the new AI Performance report
surfaces which pages are cited in AI answers, how citation visibility
changes over time, and the grounding queries associated with your
content.
Server logs are the second essential data source. Use them to verify
that the expected bots are actually reaching the right URLs, and not
just your home page or a sitemap index. OpenAI publishes IP ranges for
its crawlers, and Google documents reverse-DNS and IP-range verification
for Googlebot. Anthropic’s public bot article reviewed here focuses on
robots behavior rather than verification details, so that part should be
treated as an open operational question if strict bot authentication is
required for your environment.
A modern test cycle should include five recurring checks. First, live
URL inspection for important pages after major changes. Second,
structured data validation and parity checks between visible content and
JSON-LD. Third, canonical and hreflang validation after
migrations or template updates. Fourth, media validation for images,
videos, transcripts, and PDF/HTML equivalents. Fifth, retrieval realism
tests: sample real user questions, then check whether the intended
answer section is easy to locate with your own semantic or site search
stack. Microsoft’s and Google Cloud’s chunking documentation, and recent
ACL work, all support the idea that retrieval quality is often a layout
and segmentation issue before it is a model issue.
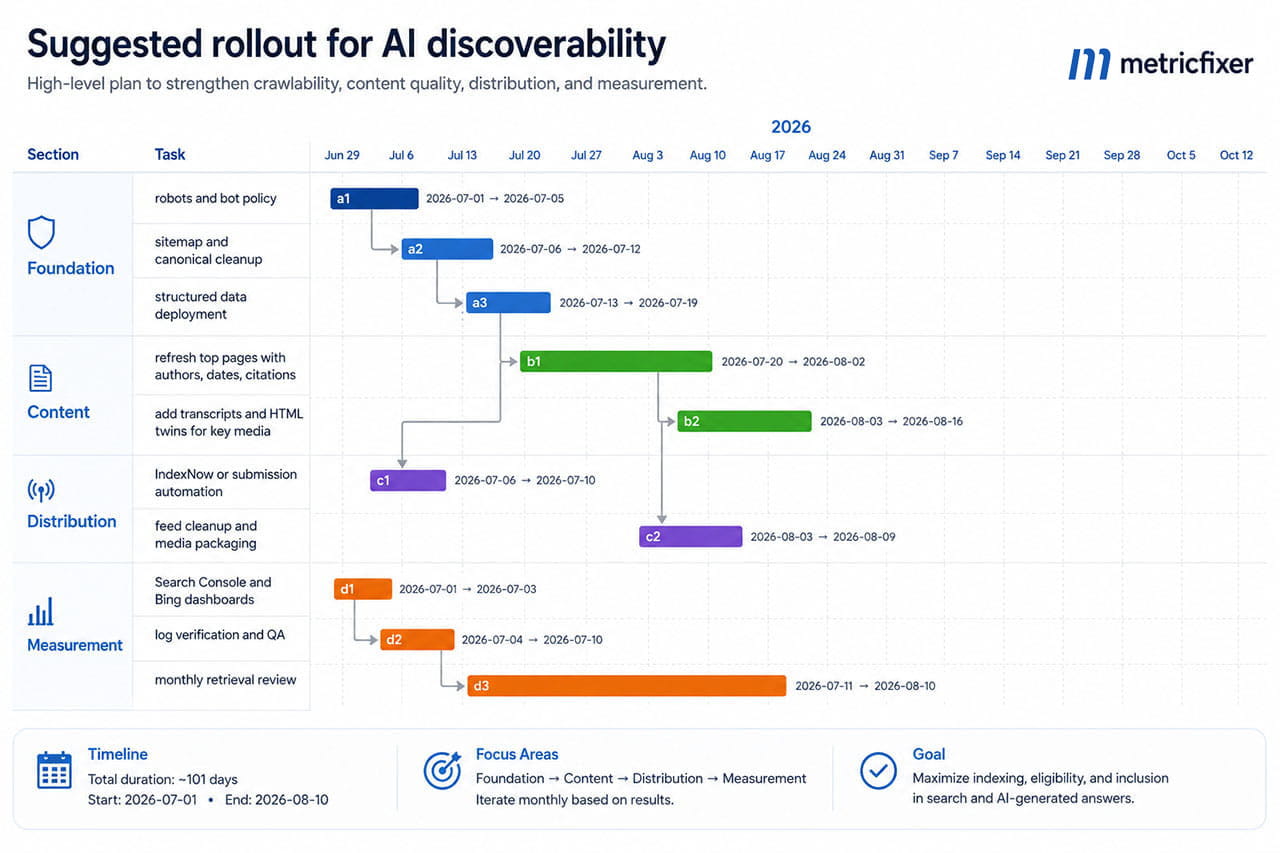
The operational timeline below is usually the right order for most organizations.
Prioritized checklist, examples, and tools
If you only take ten actions, take these ten first. They are the highest-confidence, highest-utility items across the sources reviewed.
| Priority | Action | Why it matters | Expected impact | Effort |
|---|---|---|---|---|
| Immediate | Confirm that pages you want surfaced are publicly crawlable and not blocked for the relevant bots. | OpenAI, Google, Bing, and Anthropic all depend on crawl/index eligibility for discovery. | Very high | Low |
| Immediate | Publish or clean an XML sitemap containing only canonical URLs. | Sitemaps are a discovery hint and canonical preference signal. | Very high | Low |
| Immediate | Fix canonical tags, redirects, duplicate URLs, and protocol/subdomain inconsistencies. | Duplicate ambiguity suppresses indexing clarity and citation confidence. | Very high | Medium |
| Immediate | Add JSON-LD for the main content types you publish. |
Structured data improves machine understanding and rich feature eligibility. | High | Medium |
| Immediate | Show visible author, publisher, published date, and updated date on key pages. | Freshness and provenance are major trust signals. | High | Low |
| Near-term | Rewrite top pages into answer-sized sections with clear headings. | Better chunking improves retrieval and answer grounding. | High | Medium |
| Near-term | Add first-party citations and links to primary sources for key claims. | Grounded systems prefer verifiable evidence. | High | Medium |
| Near-term | Improve internal linking from hubs, categories, glossaries, and author pages. | Internal links help discovery and topical context. | High | Medium |
| Near-term | Package media properly with transcripts, alt text, watch pages, and
Open Graph. |
Text availability and metadata improve retrieval and recommendations. | Medium to high | Medium |
| Near-term | Turn on measurement in Search Console and Bing Webmaster Tools,
including AI reports where available. |
You need page-level evidence of indexing and citations. | High | Low |
A few implementation examples can make the checklist more concrete.
If you run a legal knowledge site, each statute summary should have one
canonical HTML URL, visible jurisdiction/date metadata, a named editor,
citations to the official gazette or regulator, FAQ-style subsections
for common user questions, and a machine-readable Article
or FAQPage model where appropriate. If you run a B2B
software site, each product page should connect to comparison pages,
pricing, integrations, implementation guides, security docs, and case
studies through crawlable internal links, with consistent naming across
titles, headings, structured data, and Open Graph tags. If you run a
media-heavy site, every video should live on a dedicated watch page with
transcript text, VideoObject markup, a stable thumbnail,
and a short HTML summary that can be quoted even when the full video is
not watched.
Recommended official tools are straightforward. For Google: Search
Console, URL Inspection, Rich Results Test, the Generative AI
performance report, and the Search Console API. For Bing/Microsoft: Bing
Webmaster Tools, Site Explorer, URL Inspection, AI Performance, Crawl
Control, IndexNow, and the URL Submission API. For OpenAI: crawler
documentation for robots and the Apps SDK if you want assistant-native
usability. For Anthropic: bot documentation for
Claude-SearchBot, Claude-User, and
ClaudeBot. For Meta and recommendation surfaces: the Open
Graph protocol and Meta Sharing Debugger.
The most important assumption behind this report is that the site’s goal is earned visibility in answer engines and recommendations, not paid placement or closed-platform distribution. The strongest official guidance reviewed here supports that goal through crawlability, content clarity, and rights controls — not through hidden “GEO” hacks. In fact, Google’s current position is that standard SEO remains the right baseline for AI features, and Bing’s position is that the same discovery, indexing, and authority signals support grounding and citations. If you remember one sentence from this entire report, make it this: build pages that an AI system can confidently fetch, segment, verify, and cite.
Open questions and limitations
Some platform details remain less transparent than others. In
particular, Meta’s public, publisher-facing guidance in the reviewed
sources is much clearer for Open Graph recommendation metadata than for
AI-specific crawler participation, so any Meta-specific “AI indexing”
strategy should be treated cautiously unless confirmed from newer
official documentation.
Anthropic’s reviewed public documentation clearly documents bot roles
and robots behavior, including Crawl-delay, but it does
not, in the sources reviewed here, provide the same level of published
bot verification detail that Google and OpenAI do. If your site requires
strict bot authentication, that is a point to validate before deploying
bot-specific firewall rules.
Google’s Search generative AI controls and reporting are still
rolling out by property in 2026, so not every site owner will yet see
the same reports or controls in Search Console. Bing’s AI Performance
reporting is also relatively new, which means benchmark history will be
limited for many sites.